Optimization-inspired Deep Learning — Past Projects
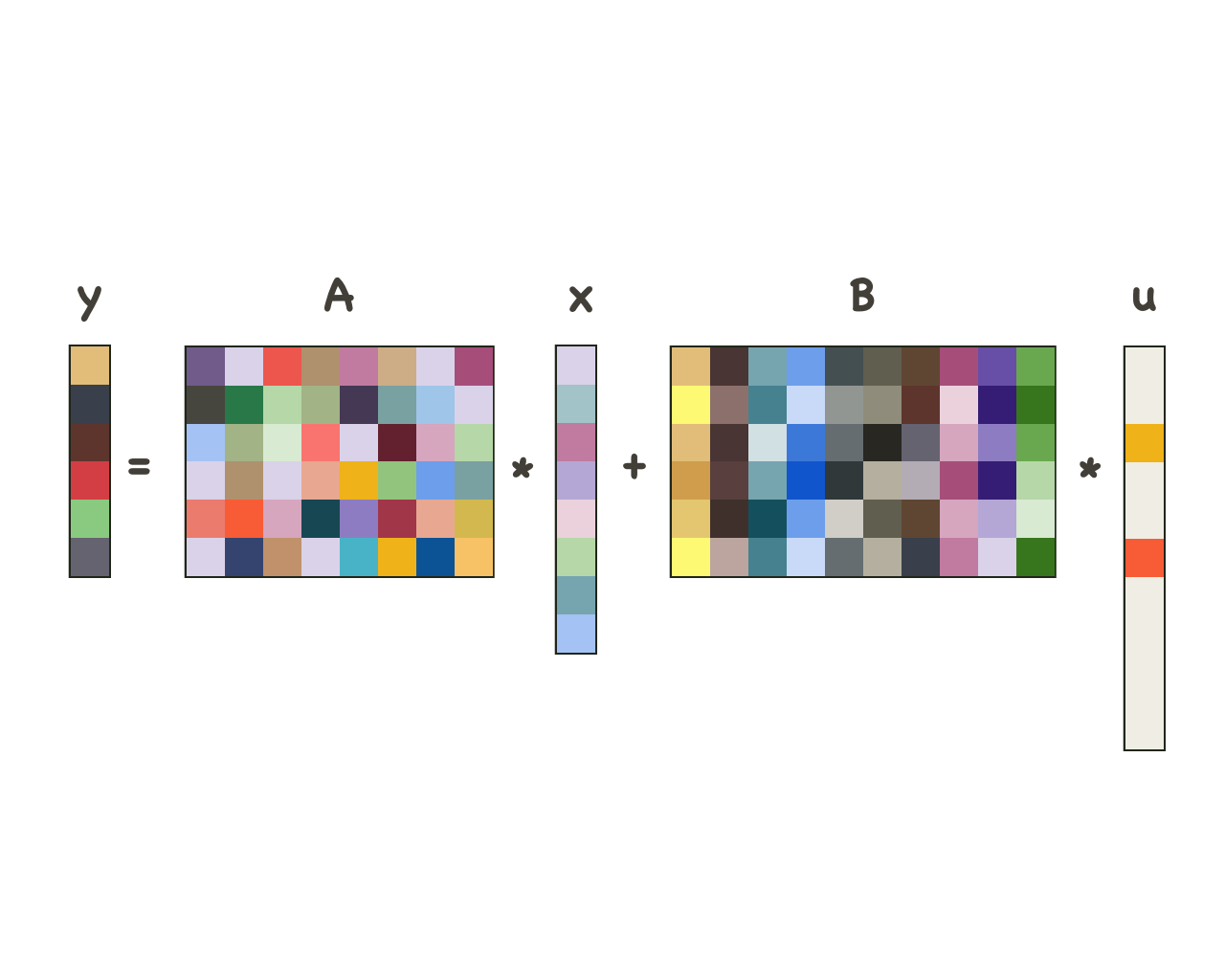
Sparse and dense models
In signal processing images are frequently thought of being decomposable into a dense, or low-frequency, and a sparse, or high-frequency, component, possibly at different levels of granularity. Based on this observation, we design, experiment on, and provide proofs for a new computational model and a corresponding deep-learning architecture. This sparse and dense model is able to accurately recover both the sparse and dense components, and the deep-learning architecture exhibits a similar performance.
Relevant papers
[1] Tasissa A., Theodosis E., Tolooshams B., Ba D. "Dense and sparse coding: theory and
architectures", arXiv, 2020.
[2] Zazo J., Tolooshams B., Ba D. "Convolutional dictionary learning in hierarchical networks",
IEEE International Workshop on Computational Advances in Multi-Sensor Adaptive
Processing, 2019.
Main researchers: Abiy Tasissa, Manos Theodosis, Javier Zazo
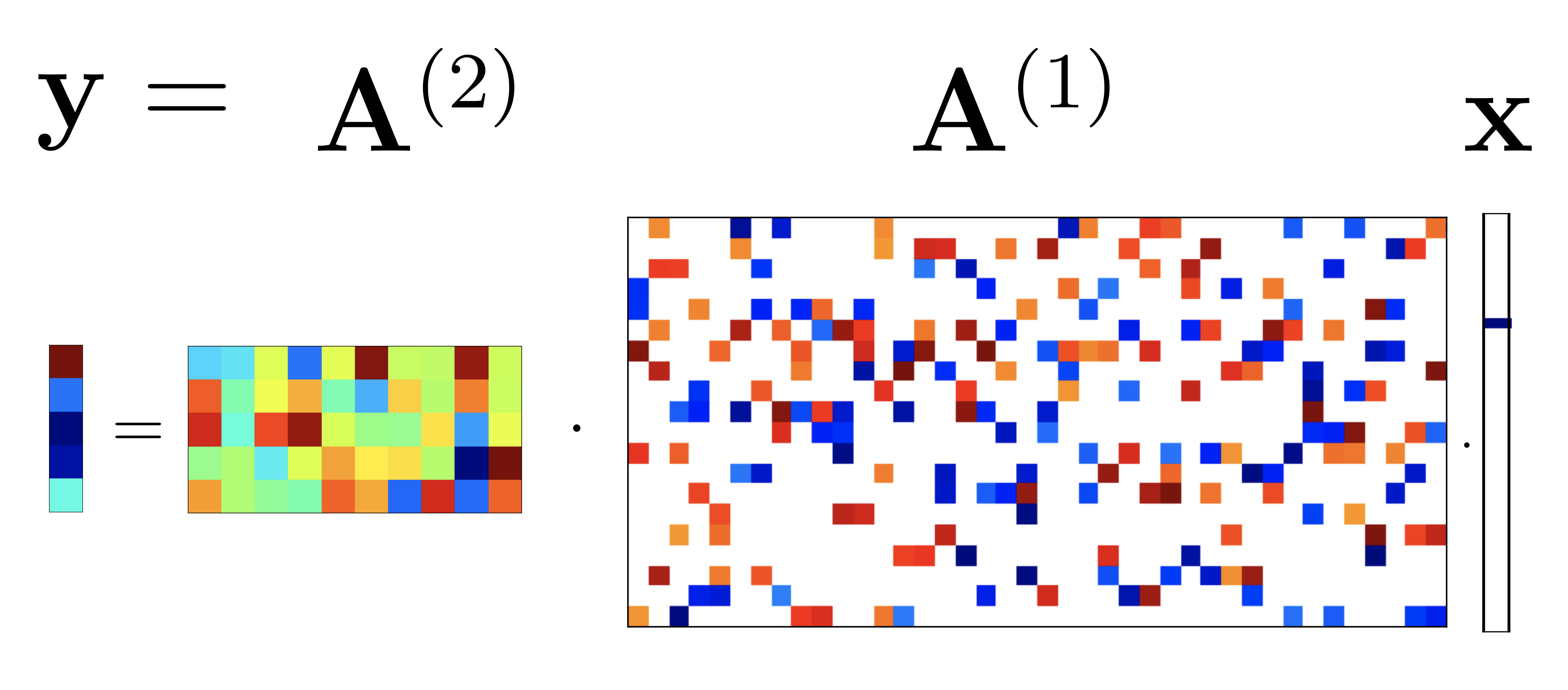
Deeply-sparse signal representations
A recent line of work shows that a deep neural network with ReLU nonlinearities arises from a finite sequence of cascaded sparse-coding models, the outputs of which, except for the last element in the cascade, are sparse and unobservable. We show that if the measurement matrices in the cascaded sparse-coding model satisfy certain regularity conditions they can be recovered with high probability. The method of choice in deep learning to solve this problem is by training an auto-encoder. Our algorithms provide a sound alternative, with theoretical guarantees, as well upper bounds on sample complexity. The theory 1) relates the number of examples needed to learn the dictionaries to the number of hidden units at the deepest layer and the number of active neurons at that layer (sparsity), 2) relates the number of hidden units in successive layers, thus giving a practical prescription for designing deep ReLU neural networks, and 3) gives some insight as to why deep networks require more data to train than shallow ones.
Relevant papers
[1] Ba D. "Deeply-sparse signal representations", IEEE Transactions on Signal Processing,
2020.
Main researchers: Demba Ba
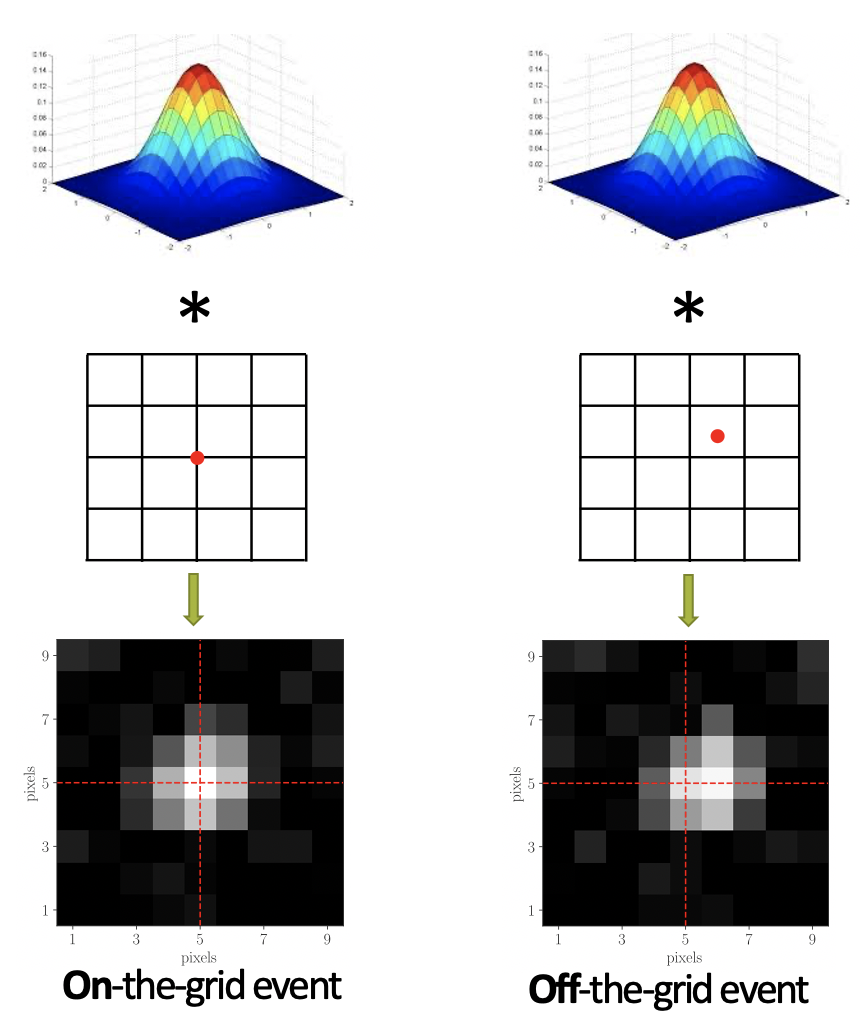
Smoothness-constrained dictionary learning
Many real-world applications, especially the biological data from electrophysiology or super-resolution microscopy experiments, can be decomposed into superposition of smooth, localized dictionary elements. By incorporating the smoothness constraint explicitly into our dictionary learning optimization procedure, we are able to 1) learn more accurate dictionary elements and 2) perform super-resolve temporal/spatial uncertainty.
Relevant papers
[1] Song A., Flores F., Ba D. "Convolutional dictionary learning with grid refinement", IEEE
Transactions on Signal Processing, 2020.
Main researchers: Andrew Song
Learning behaviour of exponential autoencoders
We introduce a deep neural network called deep convolutional exponential autoencoder (DCEA) adapted to various data types such as count, binary, or continuous data. The network architecture is inspired from convolutional dictionary learning, the problem of learning filters that entail locally sparse representations of the data. When the data is continuous and corrupted by Gaussian noise, DCEA is reduced to constrained recurrent sparse autoencoder (CRsAE). DCEA is one of the state-of-the-arts in low count Poisson image denoising. In addition, compared to optimization-based methods, CRsAE and DCEA accelerates dictionary learning as a result of implicit acceleration caused by backpropagation and its deployment on GPU. Besides, we study the learning behaviour of DCEA during training.
Relevant papers
[1] Tolooshams B.†, Song A.†, Temereanca S.,
Ba D. "Convolutional dictionary learning based auto-encoders for natural exponential-family
distributions", International Conference on Machine Learning, 2020.
Main researchers: Bahareh Tolooshams, Andrew Song
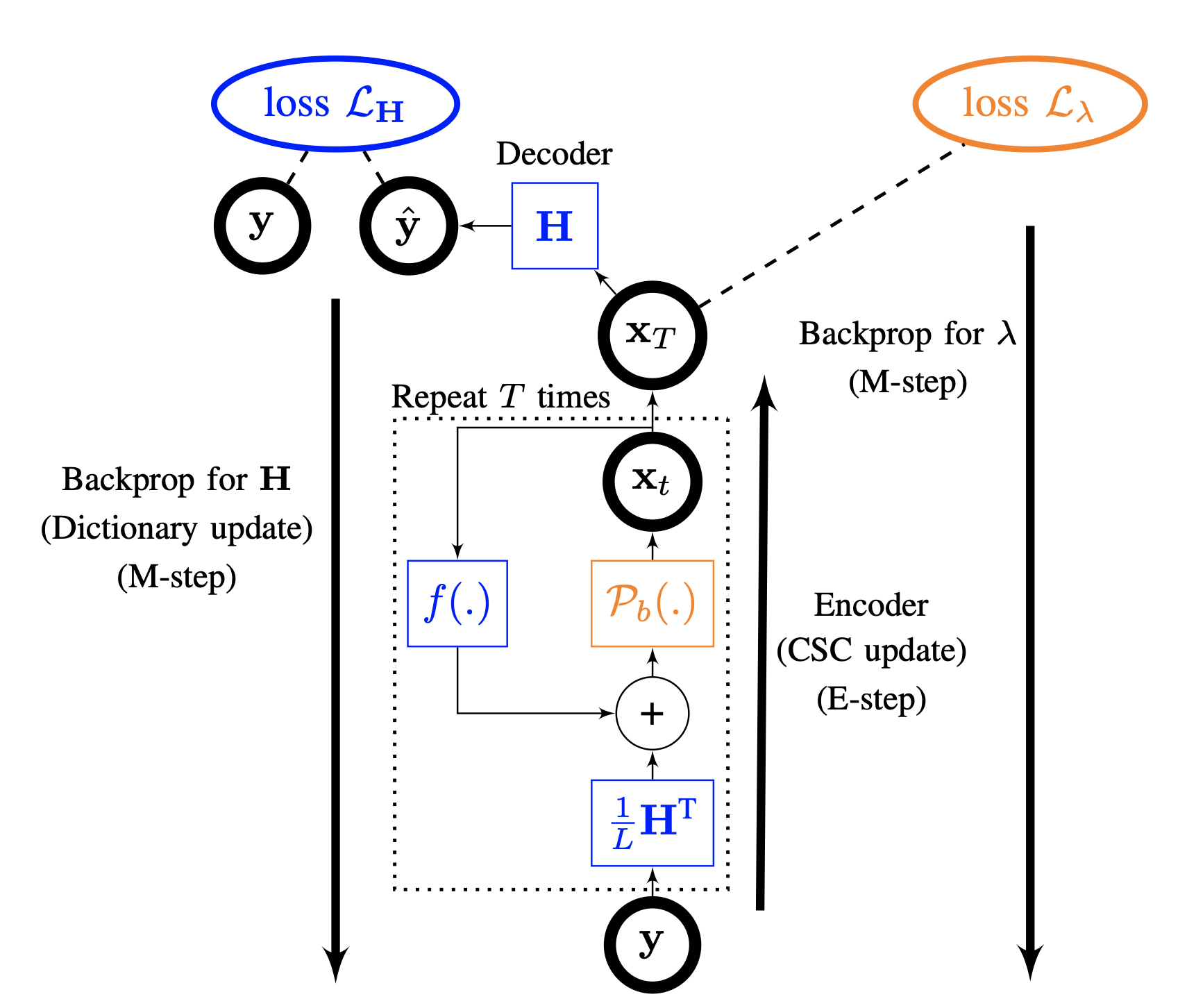
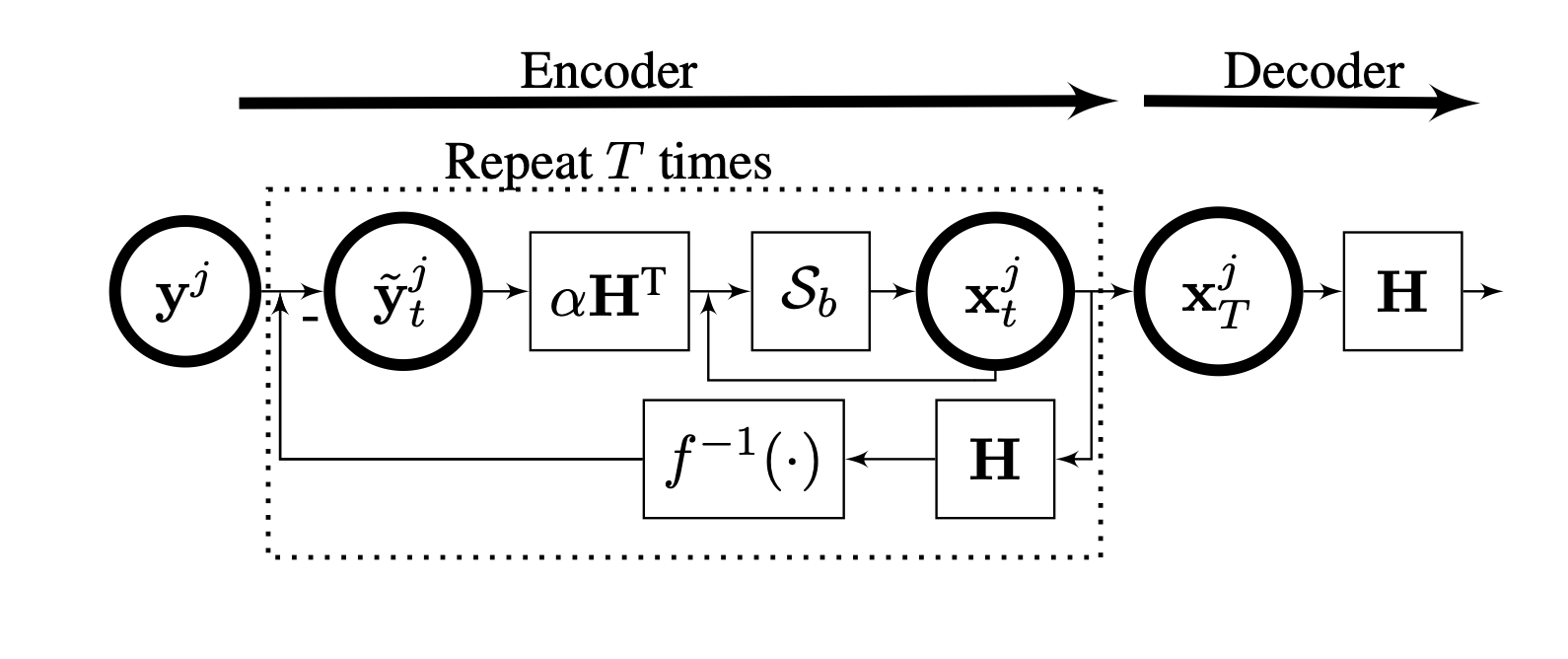
Model-based autoencoders for dictionary learning
We introduce constrained recurrent sparse autoencoder (CRsAE) based on dictionary learning. The encoder maps the data into a sparse representation and the decoder reconstructs the data using a dictionary. In cases where you only have access to a compressed version of the data, the network is named RandNet. RandNet tries to recover data from its compressed measurements using sparsity prior.
Relevant papers
[1] Tolooshams B., Dey S., Ba D. "Deep residual auto-encoders for expectation
maximization-inspired dictionary learning", IEEE Transactions on Neural Networks and Learning
Systems, 2020.
[2] Chang T., Tolooshams B., Ba D. "Randnet: deep learning with compressed measurements of
images", International Workshop on Machine Learning for Signal Processing, 2019.
[3] Tolooshams B., Dey S., Ba D. "Scalable convolutional dictionary learning with constrained
reccurent sparse auto-encoders", International Workshop on Machine Learning for Signal
Processing, 2018.
Main researchers: Bahareh Tolooshams