Interpretable Artificial and Natural Intelligence — Current Projects
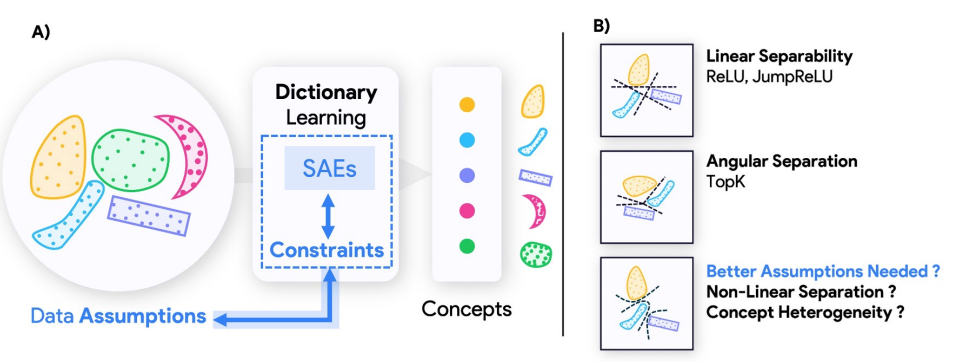
Geometry-Aware Sparse Autoencoders for Mechanistic Interpretability
Sparse autoencoders (SAEs) have become a central tool for mechanistic interpretability, decomposing neural network activations into human-interpretable concepts. However, the geometric assumptions built into current SAEs directly shape what features they can extract, often failing to capture concepts that are nonlinearly separable, hierarchically organized, or exhibit heterogeneous sparsity. This research introduces complementary architectures—MP-SAE, which leverages unrolled Matching Pursuit to extract hierarchical features in highly coherent dictionaries, and SpaDE, designed to recover nonlinearly separable concepts with heterogeneous sparsity. Our work demonstrates that each SAE architecture imposes structural assumptions about concept encoding, suggesting that interpretability should be guided not by one-size-fits-all tools, but by inductive biases that reflect the structure of neural representations.
Relevant papers
[1] Costa V., Fel T., Lubana E. S., Tolooshams B., Ba D. "From flat to hierarchical: Extracting
sparse
representations with Matching Pursuit", Neural Information Processing Systems, 2025.
[2] Costa V., Fel T., Lubana E. S., Tolooshams B., Ba D. "Evaluating sparse autoencoders: From shallow design to matching pursuit", ICML Workshop on Methods and Opportunities at Small Scale (MOSS), 2025.
[3] Hindupur S. S. R., Lubana E. S., Fel T., Ba D. "Projecting assumptions: The duality between
sparse
autoencoders and concept geometry", Neural Information Processing Systems, 2025.
Main researchers: Valerie Costa, Sumedh Hindupur, Ekdeep Singh Lubana, Thomas Fel

Understanding Vision Transformers Through Dynamics and Geometry
Vision Transformers (ViTs) have revolutionized computer vision, but understanding their internal mechanisms remains a challenge. This research program applies dynamical systems analysis and geometric interpretability tools to decode how ViTs process and organize visual information. We demonstrate that trained ViTs admit a block-recurrent depth structure where extensive layers can be replicated using fewer recurring blocks, achieving comparable performance to models like DINOv2 while significantly reducing computational complexity. By investigating how DINOv2 organizes learned concepts, we discover that different tasks recruit specialized concepts and propose the Minkowski Representation Hypothesis, suggesting tokens are formed through convex mixtures of archetypes rather than purely sparse representations. Our work reveals predictable, convergent patterns in how information flows through Vision Transformers, grounding these insights in geometric principles and attention mechanisms.
Relevant papers
[1] Jacobs M., Fel T., Hakim R., Brondetta A., Ba D., Keller T. A. "Block-recurrent dynamics in
vision transformers", To appear at the International Conference on Learning Representations, 2026.
[2] Fel T., Wang B., Lepori M. A., Kowal M., Lee A., Balestriero R., Joseph S., Lubana E. S.,
Konkle T., Ba D., et al. "Into the rabbit hull: From task-relevant concepts in DINO to Minkowski
geometry", arXiv preprint arXiv:2510.08638, 2025.
Main researchers: Mozes Jacobs, Thomas Fel, Richard Hakim, Binxu Wang
Understanding Creativity in Diffusion Models
How do diffusion models generate images that remain plausible while differing significantly from their training data? This research program develops theoretical frameworks to understand the origins of creativity in diffusion models by analyzing how architectural choices and inductive biases shape generative behavior. We show that in diffusion models with simple CNNs, translation equivariance and locality allow the model to generate patch-wise mosaics differing from training data, while self-attention induces globally image-consistent arrangements beyond the patch level. By providing an interpretable wavelet-based parameterization of diffusion scores, we reveal that images exhibit power-law spectral decay and sparse wavelet coefficients, with models learning to correct more strongly along low-variance modes. Our work also proposes a geometric definition of artistic style in terms of symmetries and texture, addressing the gap between optimization-based and diffusion-based approaches to style transfer and offering theoretical grounding for how models capture and transfer artistic signatures.
Relevant papers
[1] Finn E., Keller T. A., Theodosis E., Ba D. "Origins of creativity in attention-based
diffusion
models", ICML Workshop on High-dimensional Learning Dynamics, 2025.
[2] Finn E., Wang B., Keller T. A., Ba D. "Where the score lives: A wavelet view of diffusion",
NeurIPS Workshop on Structured Probabilistic Inference and Generative Modeling, 2025.
[3] Wang B., Finn E., Liu B. "When rule learning breaks: Diffusion fails to learn parity of many bits",
NeurIPS Workshop on Structured Probabilistic Inference and Generative Modeling, 2025.
[4] Finn E., Keller T. A., Theodosis E., Ba D. "Learning artistic signatures: Symmetry discovery
and style transfer", arXiv preprint arXiv:2412.04441, 2024.
Main researchers: Emma Finn, Andy Keller, Manos Theodosis, Binxu Wang
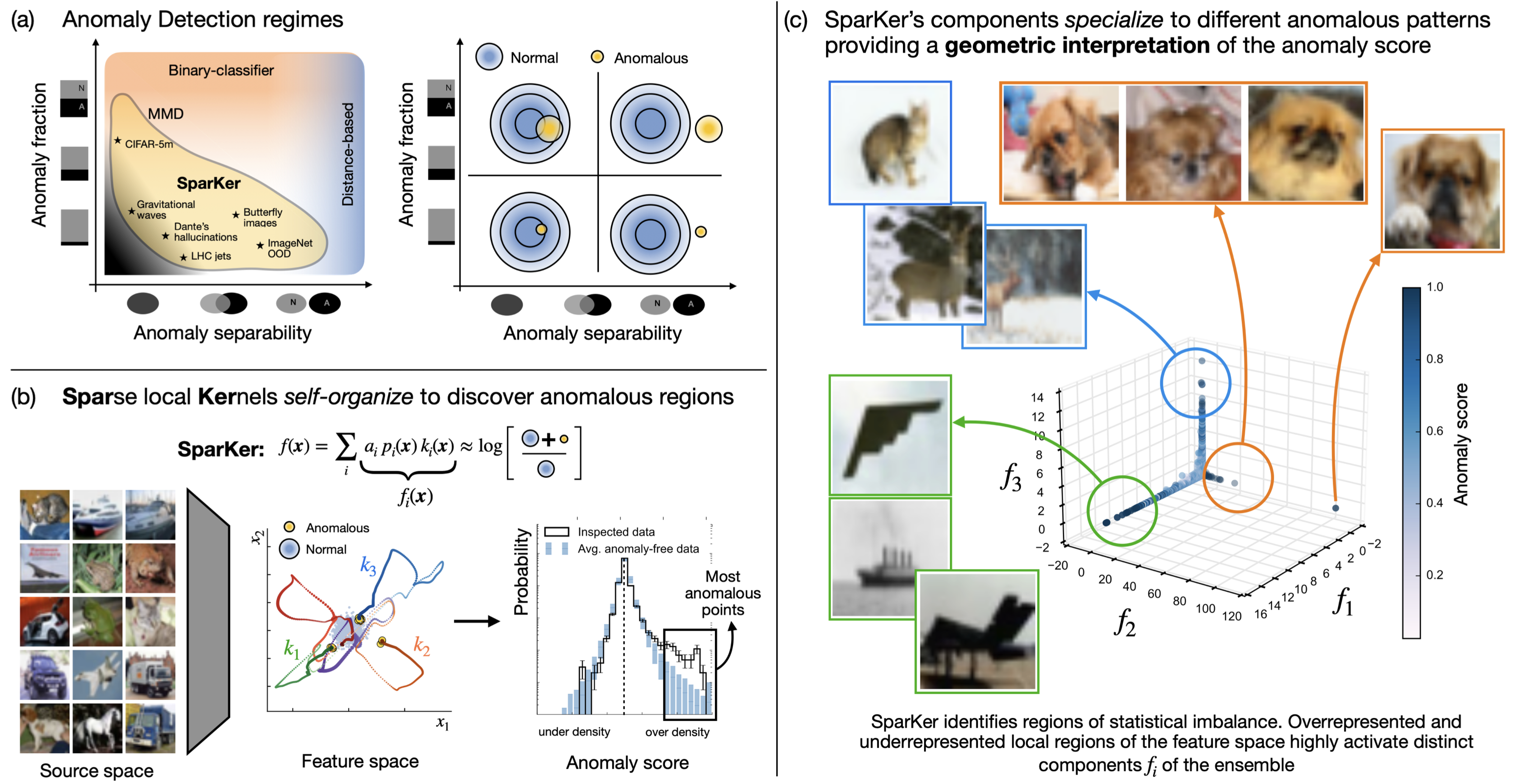
Self-Organizing Anomaly Detection in High-Dimensional Spaces
Anomaly detection plays a central role in discovery, validation, and monitoring across science and modern AI, but standard deep learning approaches are often poorly suited to challenging detection regimes. This project introduces a kernel-based model that combines sparsity, locality, and competition to address this gap. Using a small ensemble of Gaussian kernels to construct local anomaly scores in a semi-supervised fashion, our method allows kernels to self-organize over the data and compete for attention, focusing computational resources where anomalies are most likely to occur. We provide theoretical insights into the mechanisms behind detection and kernel self-organization, and validate the approach across diverse domains including physics, computer vision, and language. Remarkably, even with only a handful of kernels, the method reliably identifies anomalous locations in representation spaces of thousands of dimensions, highlighting both its scalability and ability to provide intelligible insights into complex data.
Relevant papers
[1] Grosso G., Hindupur S. S. R., Fel T., Bright-Thonney S., Harris P., Ba D. "Sparse,
self-organizing ensembles of local kernels detect rare statistical anomalies", arXiv preprint
arXiv:2511.03095, 2025.
Main researchers: Gaia Grosso, Sumedh Hindupur, Thomas Fel
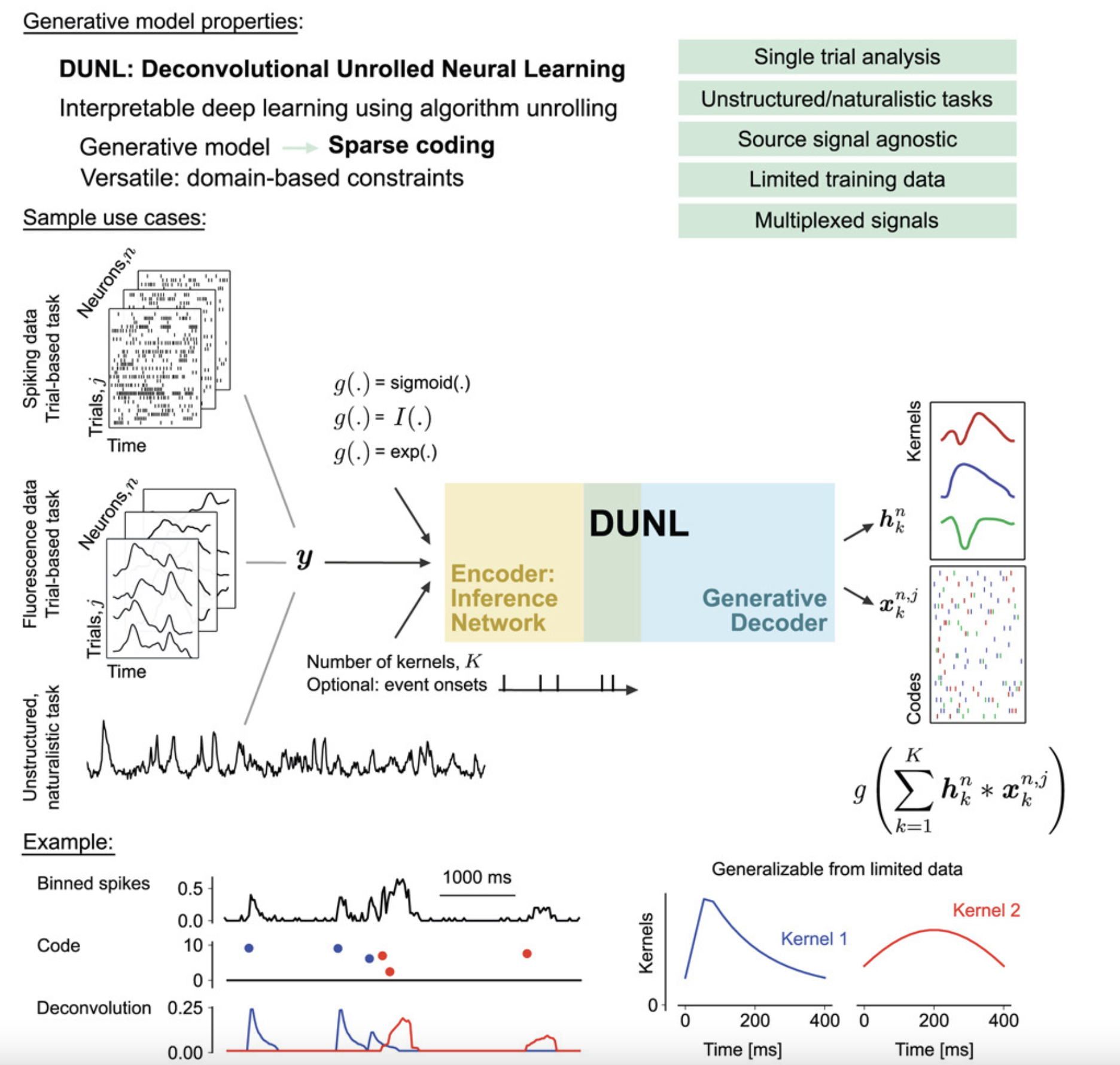
Interpretable Deep Learning for Deconvolutional Analysis of Neural Signals
The widespread adoption of deep learning to model neural activity often relies on "black-box" approaches that lack an interpretable connection between neural activity and network parameters. This project proposes using algorithm unrolling, a method for interpretable deep learning, to design the architecture of sparse deconvolutional neural networks. The resulting method, deconvolutional unrolled neural learning (DUNL), obtains a direct interpretation of network weights through a generative model and deconvolves neural data into a sparse set of interpretable, local components. DUNL is applied to uncover multiplexed salience and reward prediction error signals from midbrain dopamine neurons, perform simultaneous event detection and characterization in somatosensory thalamus recordings, and characterize the heterogeneity of neural responses in piriform cortex and striatum during naturalistic experiments.
Relevant papers
[1] Tolooshams B.†, Matias S.†, Wu H., Murthy V. N., Masset P., Ba D. "Interpretable deep learning for deconvolutional analysis of neural signals", Cell Reports Methods, 2023.
Main researchers: Bahareh Tolooshams, Paul Masset
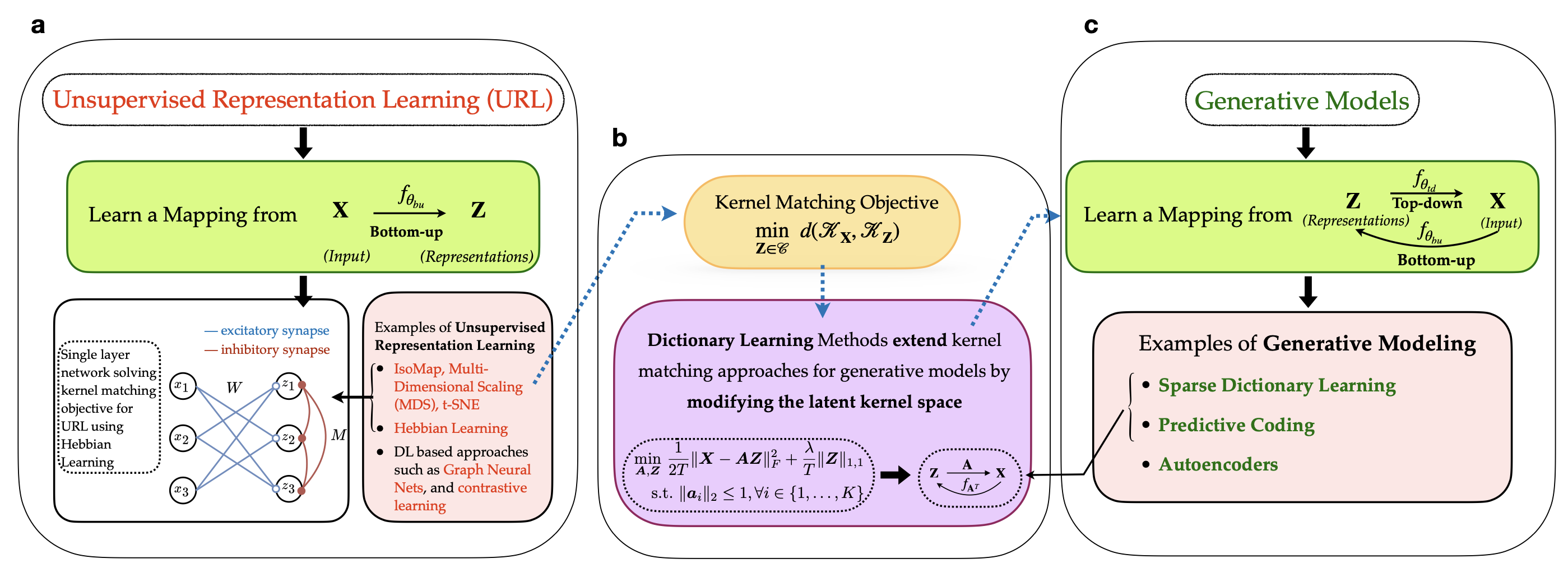
Implicit Generative Modeling by Kernel Similarity Matching
Brains don't just recognize patterns—they also predict what they will see. We propose a self-supervised framework that learns representations by aligning the similarity geometry of inputs with a learned latent space, and in doing so, reveals an implicit generative model that maps latent representations back to sensory data. Our key insight is an equivalence between kernel similarity matching objectives and dictionary learning, which lets us reinterpret representation learning as a bidirectional process: bottom-up encoding from stimuli to latents, coupled with top-down prediction from latents to stimuli. This perspective links modern similarity-based learning to biologically grounded ideas like predictive coding, offering a new route toward interpretable and neurally plausible representation learning.
Relevant papers
[1] Choudhary S., Masset P., Ba D. "Implicit generative modeling by kernel similarity matching", In Press, Neural Computation, 2026. [arxiv]
[2] Choudhary S., Masset P., Ba D. "Self supervised dictionary learning using kernel matching", IEEE International Workshop on Machine Learning for Signal Processing, 2024. [official]
Main researchers: Shubham Choudhary, Paul Masset
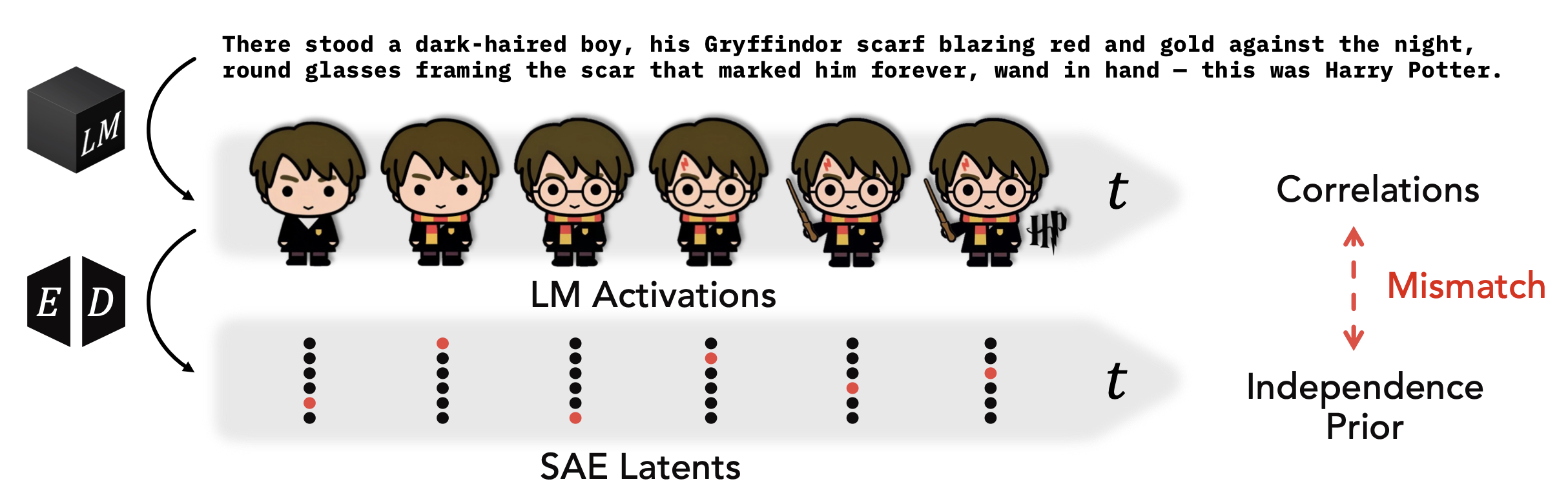
Temporal Structure in Language Model Interpretability
Current interpretability methods like Sparse Autoencoders (SAEs) impose priors that assume independence of concepts across time, overlooking the rich temporal structure inherent to language models. This research investigates how SAEs fail to capture the temporal dynamics of language model representations and introduces Temporal Feature Analysis, a new interpretability method that decomposes activations into predictable and novel components. By better handling the non-stationary nature of language, our work reveals that language models exhibit temporal dependencies that fundamentally shape their representations, suggesting that interpretability tools must account for the sequential nature of language processing to provide accurate insights into model behavior.
Relevant papers
[1] Lubana E. S., Rager C., Hindupur S. S. R., Costa V., Tuckute G., Patel O., Murthy S. K.,
Fel T., Wurgaft D., Bigelow E. J., et al. "Priors in time: Missing inductive biases for language
model interpretability", International Conference on Learning Representations, 2026.
Main researchers: Ekdeep Singh Lubana, Sumedh Hindupur, Valerie Costa